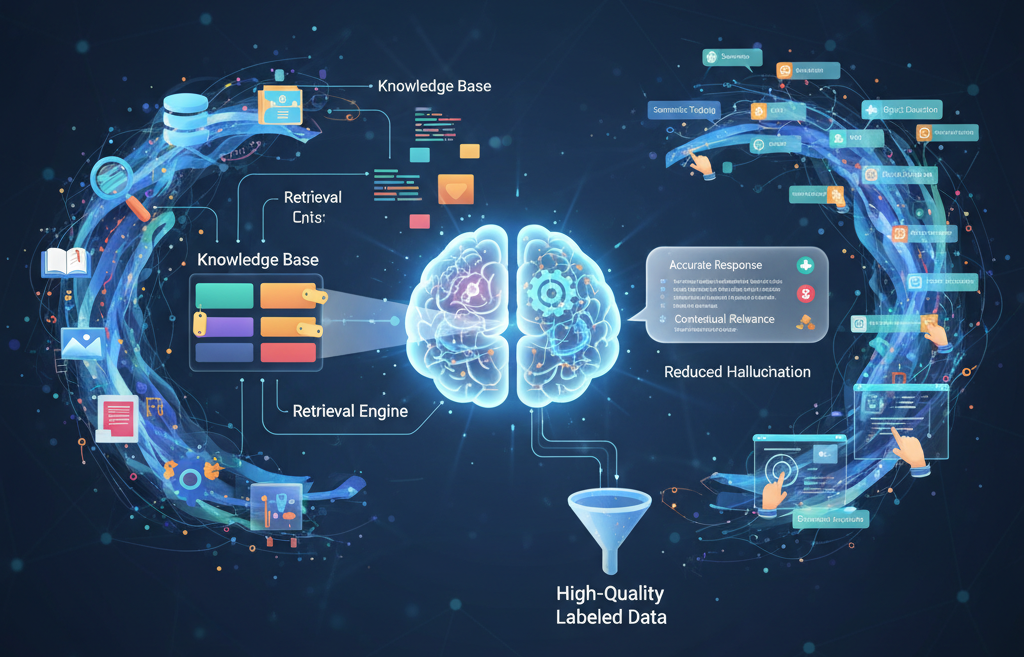
LLM-AS-A-JUDGE VS. HUMAN EVALUATION
In the world of machine learning (ML) and artificial intelligence (AI), the idea of using large language models (LLMs) as evaluators or “judges” has gained traction. These AI-driven models are already powering numerous applications, from content generation to real-time translations. But how do they fare when it comes to the more nuanced process of evaluation? […]
LLM-AS-A-JUDGE VS. HUMAN EVALUATION Read More »