
“One of the first areas artificial intelligence will take many jobs is transportation. Bus drivers, truckers, taxicab drivers… need to start thinking about new careers.”
– Dave Waters
Here Dave Waters pointed out the concept of autonomous vehicles. Cutting-edge technologies like Artificial Intelligence and Machine Learning have made machines independently carry out most of the tasks done by humans and even outperform them in some others. The concept of autonomous driving had been “unimaginable” until recently, but not anymore. According to the latest reports from many perception prototypes, it has now become a “definitely possible” thing.
Computer vision is the major feature that made this dream a reality. What is computer vision? Let’s demystify it. Computer vision is a subclass of artificial intelligence and machine learning enabling a smarter image/video analysis. In layman’s terms, it is the technique that helps machines to “see and interpret” our world. The technique is analogous to the human visual system with which humans examine their surroundings and make decisions. With computer vision now computers are also able to identify and process an image or video they capture.
What is Computer Vision?
Where does computer vision is applied? Anywhere where machines need to see and interpret the data. For example, consider search engines and social platforms like Facebook. Everyday users from various sources upload an infinite number of images and videos to it. For a long time unlike the text data, which could be easily interpreted, images and videos were not interpretable. Also, most of the time they were classified according to the descriptions and titles assigned to them. With computers, vision machines are now able to unlock the meaning of images and videos and index them properly. As visual data is taking the world by storm, the development of computer vision has also become a necessity. Other common examples of computer vision models include higher-level applications like autonomous vehicles, robotics, etc.
Traditional Computer Vision Vs Deep Learning
Computer vision approaches are broadly classified into two, namely, Traditional Computer Vision and Deep Learning approach. Moreover for a better understanding let us consider computer vision as a 3 block system consisting an Input, Feature engineering, and Output blocks.
It is the step of feature engineering that distinguishes conventional methods from the latest techniques. Feature engineering includes feature learning and classification. In the traditional computer vision approach, both these were done separately as shown in the figure. However, manual learning and engineering have to be done on every image consisting of diverse objects and classes. Hence, this made the works of feature engineering very cumbersome in nature. In fact, the deep learning approach made the process lot easier. Learning and classification were included in a single entity known as Deep Neural Networks.
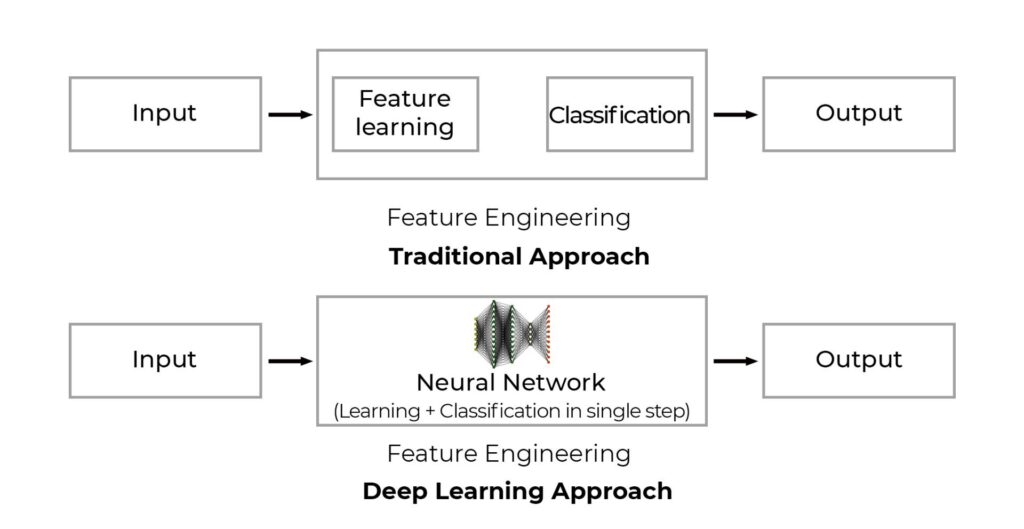
Traditional computer vision methods use techniques like SIFT, SURF, BRIEF, etc. Thus, using these techniques several simple tasks like edge detection, curve detection, etc. can be carried out more efficiently. However, for complex tasks and large data sets conventional methods to become primitive. In fact, this is where the Deep Learning approach comes into action.
Deep Learning In Computer Vision
Deep learning in computer vision has helped machines to improve their accuracy (a recent report says around 90+%) in visual interpretation tasks. Convolutional Neural Network is the technique that enables deep learning in computer vision. The network consists of numerous nodes characterizing various features as weights in it. The network first learns the features of the image and then classifies the image accordingly. Hence CNN does both the steps simultaneously. These networks constantly updates values with new values obtained while interacting with new input. For a detailed understanding of how neural networks works take a look at our Neural Networks blog.
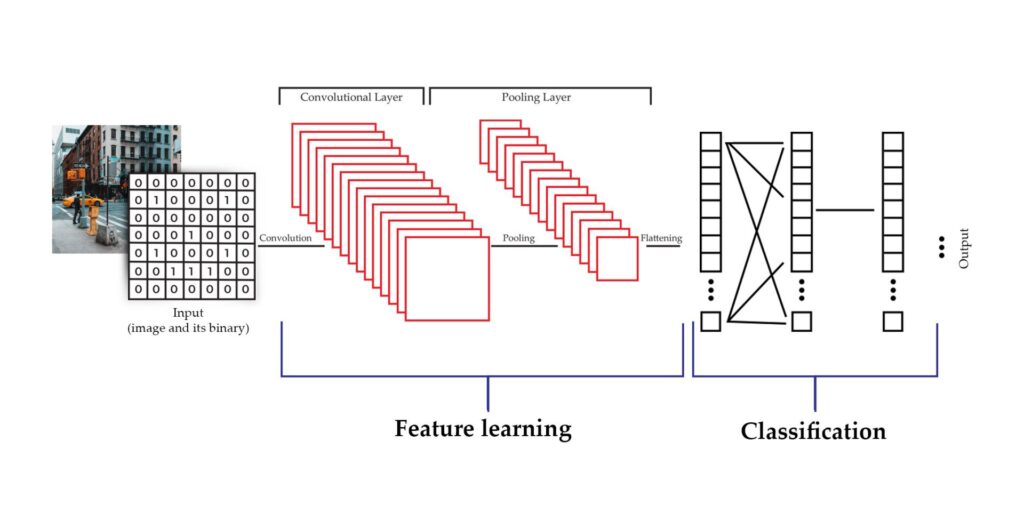
Computer Vision Tasks
Basic data interpretation methods of computer vision include Image classification, object localization, object detection, and Segmentations. To illustrate, let’s have a brief look at these basic tasks of computer vision.
Image Classification
Images are classified based on the objects in it irrespective of its location in the image. The task is a single object type. If image contains only a single object, the image is tagged with that label. Similarly, if the image contains multiple objects, the image is tagged with the label that corresponds to the most visible (or “main”) single object.

Object Localization
This is the task of defining the location of a particular object in an image using bounding boxes. Images are classified based on the object in it. Again this is a single object type and if image contains multiple objects then the most visible(or “main”) single object is localized.

Object Detection
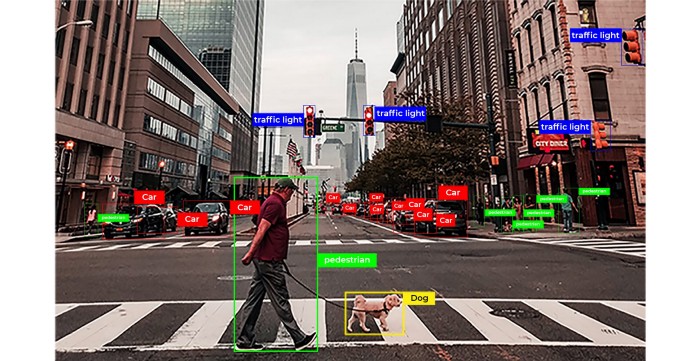
It is a combination of classification and localization. But unlike the other two this is a multiple object type. Hence instances of every object in an image are labeled, usually using bounding boxes. The autonomous vehicle is a fine example of object detection.
Segmentation
Here the model segment an image at its pixel and also helps the machines to drive meaningful insights. The two types of segmentation are standard segmentation and instance segmentation. In semantic or standard segmentation, all similar objects are given the same label and id (i.e represented using the same color). While in instance segmentation, every object of a similar class are given different id’s so as to represent different instances(ie represented using a different color). To illustrate an example of both are shown below.
Computer Vision In Autonomous Vehicle
The autonomous vehicle is one of the greatest applications of computer vision. Also, for enabling a safe drive, the technique helps these prototypes in the detection and recognition of traffic signs, traffic lights, pedestrians, adjacent vehicles, lanes, etc.
Object Detection In AV
Object detection is basically the combination of object classification and object localization. As autonomous vehicles need to deal with multiple objects on roads simultaneously object detection will be the most effective method. Object detection in autonomous vehicles are usually done using bounding boxes. Perfectly enclosed and labeled bounding boxes teaches perception models what is what and what decision to take when. From bounding boxes, the model extracts box parameters like labels, box height, box width, etc for gaining needful insights from it.

A bounding box isn’t enough for a CV model in Autonomous vehicles to work. Conventionally, CNN used the sliding window technique to learn the art of object detection. Images are first divided into small squares or sections. The algorithm then searches for the required object in these segments. Hence, this helps the machine to narrow down its search on the image. But as tasks kept on evolving more complexities like real-time video detection, etc. need for advanced techniques like YOLO (You Only Look Once) also increased. As computer vision is a vast topic, discussion of such techniques might take you off-road now and are also out of our current discussion scope.
Segmentation In AV
Segmentation is another approach to computer vision. Here it helps the perception models to the segment it’s surrounding at pixel level and derives a better insight from what it sees. In object detection parameters like box labels, box parameters, etc, are fed into models for image interpretation. In the case of segmentation, a pixel segmented image is generated for model functioning. Even for us rather than some box parameters like Xmin and Ymin a good pixel segmented image would make more sense and so for machines too. Both are effective in their own way and are choice of its usage vary according to the nature of their application.

What We Do?
So far we have discussed what computer vision is and even took an application of it for better understanding. Image Annotation is an important step in enabling these computer vision tasks. Specifically, It is the act of labeling images generating training data for such models. Furthermore, read here to learn more about what is Image Annotation. We process quality training data utilizing various annotation techniques with our highly experienced team of annotators. Got to annotate? Feel free to let us know about your annotation needs.
In conclusion, as we said CV tasks range from QR code scanning to even disease detection. Thanks to google. Recently, Google’s CV has figured out the math to detect diabetic retinopathy just from the retinal images. And it has proven to be better than well-qualified and experienced ophthalmologists. Wondering about how far computer vision can develop? Let me know your thoughts through your comments here.